How to use Span<T> and Memory<T>

NOTE: I highly suggest to also check how to use System.IO.Pipelines in .NET. It’s a feature introduced after this article was published and that allows a better implementation of the patterns shown in the examples of this article.
Span<T> and Memory<T> are new features in .NET Core 2.1 that allow strongly-typed management of contiguous memory, independently of how it was allocated. These allow easier to maintain code and greatly improves the performance of applications by reducing the number of required memory allocations and copies.
For reasons that others can explain much better, Span<T> can only exist in the stack (as opposed to existing in the heap). This means it can’t be a field in a class or in any “box-able” struct (convertible to a reference type). Span<T> takes advantage of ref struct, a new feature in C# 7.2, making the compiler enforce this rule.
Next, I’m going to create a few usage scenarios so that you can better understand when and how to use each of these new features.
Local variables
Lets imagine we a have a service that returns a collection of objects of type Foo. The collection comes from some remote location so it comes through a stream of bytes. This means that we need to get a chunk of bytes into a local buffer, convert these into our objects and repeat this process until the end of the collection.
The following example iterates through all the collection and calculates the sum of the values in the Integer field of each item.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public long Sum()
{
var itemSize = Unsafe.SizeOf<Foo>();
Span<Foo> buffer = new Foo[100]; // alloc items buffer
var rawBuffer = MemoryMarshal.Cast<Foo, byte>(buffer); // cast items buffer to bytes buffer (no copies)
var bytesRead = stream.Read(rawBuffer);
var sum = 0L;
while (bytesRead > 0)
{
var itemsRead = bytesRead / itemSize;
foreach (var foo in buffer.Slice(0, itemsRead)) // iterate through the item buffer
sum += foo.Integer;
bytesRead = stream.Read(rawBuffer);
}
return sum;
}
Notice that buffer is allocated as an Array<Foo> but stored as a local variable of type Span<Foo>. The framework includes implicit operators that allow this conversion.
Local variables in regular methods (not using async, yield or lambdas) are allocated in the stack. This means there is no problem using Span<T>. The variable will persistent as long as its own scope, in this case, the function itself.
If you check the method signature of Stream.Read(), you’ll notice that it accepts an argument of type Span<byte>. This usually means that we would need to copy memory. Not with Span<T>. As long as T is a value-type, which is the case, you can use the method MemoryMarshal.Cast<TFrom, TTo>() that masks the buffer as another type without requiring any copy. Pass the Span<byte> to Stream.Read() but read its contents as a collection of Foo using the Span<Foo>. You can access the Span<T> using the square-bracket operator or using a foreach loop.
Because, at the end of the enumeration, the number of items read can be less than the size of the buffer, we iterate on a slice of the original buffer. Slice() is a method that returns another Span<T> for the same buffer but with different boundaries.
Note that, besides the Stream.Read(), there are no memory copies. Just maskings of the same buffer. This results in major performance improvements relative to the memory managers we had before. All this with type safety and easy to maintain code.
stackalloc
Notice from the previous example that the Span<T> has to reside in the stack but not its content. The array is allocated in the heap.
Because, in this case, the buffer doesn’t have to outlive the function and is relatively small, we can allocate the buffer in the stack using the stackalloc keyword.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public long Sum()
{
var itemSize = Unsafe.SizeOf<Foo>();
Span<Foo> buffer = stackalloc Foo[100]; // alloc items buffer
var rawBuffer = MemoryMarshal.Cast<Foo, byte>(buffer); // cast items buffer to bytes buffer (no copies)
var bytesRead = stream.Read(rawBuffer);
var sum = 0L;
while (bytesRead > 0)
{
var itemsRead = bytesRead / itemSize;
foreach (var foo in buffer.Slice(0, itemsRead)) // iterate through the item buffer
sum += foo.Integer;
bytesRead = stream.Read(rawBuffer);
}
return sum;
}
Besides the buffer allocation, all the code remains unchanged. This is one more advantage of using Span<T>. It abstracts how the contiguous memory was allocated.
ref struct
These previous examples work fine but what if you want to perform multiple operations over the collection? You’d have to replicate this code in many other places, creating a maintenance nightmare. What if we could use a foreach loop? We just need to create a struct, which is allocated in the stack, that implements IEnumerator<Foo>.
Unfortunately any value-type that implements an interface is “box-able”, which means, it can be converted into a reference-type.
Fortunately, foreach doesn’t really require the implementation of interfaces. It only requires the implementation of a method GetEnumerator() that returns an instance of an object that implements a read-only property Current and a method MoveNext(). This is actually how the enumeration of Span<T> is implemented. We can do the same for our collection.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
struct RefEnumerable
{
readonly Stream stream;
public RefEnumerable(Stream stream)
{
this.stream = stream;
}
public Enumerator GetEnumerator() => new Enumerator(this);
public ref struct Enumerator
{
static readonly int ItemSize = Unsafe.SizeOf<Foo>();
readonly Stream stream;
readonly Span<Foo> buffer;
readonly Span<byte> rawBuffer;
bool lastBuffer;
long loadedItems;
int currentItem;
public Enumerator(RefEnumerable enumerable)
{
stream = enumerable.stream;
buffer = new Foo[100]; // alloc items buffer
rawBuffer = MemoryMarshal.Cast<Foo, byte>(buffer); // cast items buffer to bytes buffer (no copies)
lastBuffer = false;
loadedItems = 0;
currentItem = -1;
}
public ref readonly Foo Current => ref buffer[currentItem];
public bool MoveNext()
{
if (++currentItem != loadedItems) // increment current position and check if reached end of buffer
return true;
if (lastBuffer) // check if it was the last buffer
return false;
// get next buffer
var bytesRead = stream.Read(rawBuffer);
lastBuffer = bytesRead < rawBuffer.Length;
currentItem = 0;
loadedItems = bytesRead / ItemSize;
return loadedItems != 0;
}
}
}
Notice the spans are not local variables but fields of the Enumerator struct. To make sure that this object is only created in the stack notice that it is declared as a ref struct. Without this, the compiler would show an error.
The creation of the spans is now in the Enumerator constructor but very similar to the first example (to my best knowledge, it’s not possible to use stackalloc in this case). The enumeration is now split into Current and MoveNext(). foreach calls the method MoveNext() to step to the next item of the collections and then calls Current to get it.
Notice that Current returns a read-only reference of type Foo. This means it accesses the item without copying it. This is also a feature of C# 7.2 that can be used to improve considerably the performance of applications.
Value types
The previous code allows the use of foreach but if you also want to allow the use of LINQ, there’s no escape from having to implement interfaces.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
public struct Enumerable : IEnumerable<Foo>
{
readonly Stream stream;
public Enumerable(Stream stream)
{
this.stream = stream;
}
public IEnumerator<Foo> GetEnumerator() => new Enumerator(this);
IEnumerator IEnumerable.GetEnumerator() => GetEnumerator();
public struct Enumerator : IEnumerator<Foo>
{
static readonly int ItemSize = Unsafe.SizeOf<Foo>();
readonly Stream stream;
readonly Memory<Foo> buffer;
bool lastBuffer;
long loadedItems;
int currentItem;
public Enumerator(Enumerable enumerable)
{
stream = enumerable.stream;
buffer = new Foo[100]; // alloc items buffer
lastBuffer = false;
loadedItems = 0;
currentItem = -1;
}
public Foo Current => buffer.Span[currentItem];
object IEnumerator.Current => Current;
public bool MoveNext()
{
if (++currentItem != loadedItems) // increment current position and check if reached end of buffer
return true;
if (lastBuffer) // check if it was the last buffer
return false;
// get next buffer
var rawBuffer = MemoryMarshal.Cast<Foo, byte>(buffer);
var bytesRead = stream.Read(rawBuffer);
lastBuffer = bytesRead < rawBuffer.Length;
currentItem = 0;
loadedItems = bytesRead / ItemSize;
return loadedItems != 0;
}
public void Reset() => throw new NotImplementedException();
public void Dispose()
{
// nothing to do
}
}
}
Notice that buffer is still stored as a field but now of type Memory<Foo>.
Memory<T> is a factory of Span<T> that can reside in the heap. It has a Span property that creates a new instance of Span<T> valid in the scope that is called.
The Enumerator cannot be a ref struct now as it implements an interface. I’m leaving it as a struct as it performs better in this case. Calling an interface method has a performance penalty because it’s a virtual call. Structs don’t allow inheritance so .NET is able to optimize these calls making them slightly faster.
The property Current now return Foo instead of a reference, which means there is a memory copy. You can add an overload that returns a reference but, any call using IEnumerator<T>, will explicitly use the other.
Performance
How do these examples perform? BenchmarkDotNet makes it very simple to compare the performance of all these scenarios.
The code for these benchmarks can be found at EnumerationBenchmarks.cs on GitHub
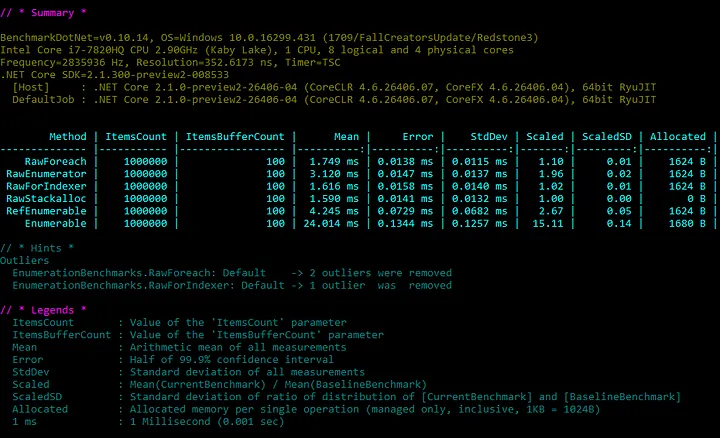
For the benchmarks, I extended the first example into 3 options of iteration on the buffer Span<>: using a foreach, using GetEnumerator() and using a for loop with indexer operator. Interesting to see that the foreach has the same performance has the for but using the GetEnumerator() is twice as slow.
Using the for loop with the buffer allocated using stackalloc is the most efficient. It takes the least time (1.6 ms) and allocates no memory on the heap. It’s set as the baseline benchmark for easier comparison.
The use of a ref struct enumerator is slower with 4.2 ms (2.67 times slower than raw stackalloc enumeration) but with reusable and easier to maintain code. This is the penalty for splitting the enumeration logic into two functions.
The use of IEnumerator<Foo> makes it substantially slower with 24.0 ms (15.11 times slower that the raw stackalloc enumeration). This case has the same penalty as the one before, plus, the use of interfaces, not returning the value by reference and not having a single Span<> for the whole enumeration.
Although not shown here, any of these solution is much faster than without the use of Span<T>. These values show that you should consider several enumeration scenarios in your applications, depending on if you favor flexibility or performance. If you are an API developer, you should expose all these so that the user can make its own choice.
Conclusion
Span<T> and Memory<T> are new features that can drastically reduce the memory copies in .NET applications, allowing performance improvements without sacrificing type safety and code readability.
You can download the source code for this article and run the benchmarks on your own system.
More info
I plan to write a few more articles on this subject but you can find a lot more info on these links:
- Welcome to C# 7.2 and Span by Mads Torgersen
- C# — All About Span: Exploring a New .NET Mainstay by Stephen Toub
- Span by Adam Sitnik
- C# 7.2: Understanding Span by Jared Parsons
- Span spec by Krzysztof Cwalina et al
- Add initial Span/Buffer-based APIs across corefx by Stephen Toub et al