ImmutableArray<T> iteration performance in C#

Introduction
ImmutableArray<T> is one of the collections provided in the System.Collections.Immutable namespace. All collections in this namespace are immutable, meaning that they cannot be altered once created.
These collections do provide mutation methods like Add(), AddRange(), Remove(), RemoveAt(), and so on. The thing is, for these collections, all these methods output a new collection, leaving the input collection unaltered.
It can be used as follow:
1
2
3
4
5
6
7
8
9
10
using System
using System.Linq;
using System.Collections.Immutable;
var array = Enumerable.Range(0, 10).ToArray();
var immutable = ImmutableArray.Create(array);
var newImmutable = immutable.Add(100);
foreach(var item in newImmutable)
Console.WriteLine(item);
You can check in SharpLab to see it working.
Value-type enumerable
I wrote on a previous article that, foreach uses the collection indexer in the case of arrays and spans. For all other cases, it uses the collection enumerator.
You can see in SharpLab that this is still true for ImmutableArray<T>. For the following code:
1
2
3
4
5
6
7
8
9
using System.Collections.Immutable
static int Sum(ImmutableArray<int> source)
{
var sum = 0;
foreach(var item in source)
sum += item;
return sum;
};
As I expected, the C# compiler generates the following:
1
2
3
4
5
6
7
8
9
10
11
12
[CompilerGenerated]
internal static int <<Main>$>g__Sum|0_0(ImmutableArray<int> source)
{
int num = 0;
ImmutableArray<int>.Enumerator enumerator = source.GetEnumerator();
while (enumerator.MoveNext())
{
int current = enumerator.Current;
num += current;
}
return num;
}
As you can see in its source code, ImmutableArray<T>.Enumerator is a value type. For these reasons, I would expect a foreach with an ImmutableArray<T> to have performance somewhat similar to the one with a List<T>.
NOTE: Check my other article “Performance of value-type vs reference-type enumerators in C#” to understand the importance of having a value-type enumerator.
Benchmarks
Let’s use BenchmarkDotNet to run the following benchmarks:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
using System;
using System.Collections.Generic;
using System.Collections.Immutable;
using System.Linq;
using System.Runtime.InteropServices;
using BenchmarkDotNet.Attributes;
public class ForEachBenchmarks
{
int[]? array;
List<int>? list;
ImmutableArray<int>? immutableArray;
[Params(10, 1_000)]
public int Count { get; set; }
[GlobalSetup]
public void GlobalSetup()
{
var range = Enumerable.Range(0, Count);
array = range.ToArray();
list = range.ToList();
immutableArray = System.Collections.Immutable.ImmutableArray.Create(array);
}
[Benchmark(Baseline = true)]
public int Array()
{
var sum = 0;
foreach (var item in array!)
sum += item;
return sum;
}
[Benchmark]
public int Array_AsSpan()
{
var sum = 0;
foreach (var item in array!.AsSpan())
sum += item;
return sum;
}
[Benchmark]
public int List()
{
var sum = 0;
foreach (var item in list!)
sum += item;
return sum;
}
[Benchmark]
public int List_AsSpan()
{
var sum = 0;
foreach (var item in CollectionsMarshal.AsSpan(list!))
sum += item;
return sum;
}
[Benchmark]
public int ImmutableArray()
{
var sum = 0;
foreach (var item in immutableArray!)
sum += item;
return sum;
}
}
It tests the performance of foreach when iterating an int[], a ReadOnlySpan<int>, a List<int>, a List<int> cast to Span<T> using CollectionsMarshal.AsSpan(), and finally an ImmutableArray<int>. It tests for a small collection of only 10 items and a larger one of 1,000 items.
I used a configuration to test for both .NET 6 and .NET 8, and obtained the following results:
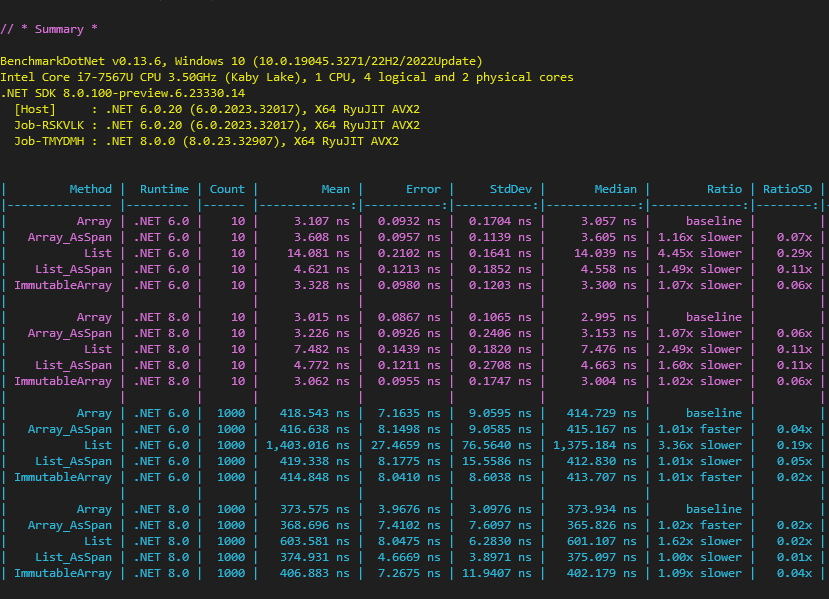
What is surprising is that the performance for ImmutableArray<int> is equivalent to the one of the int[], not to the one of the List<int>.
JIT compiler
The .NET JIT (Just-In-Time) compiler is a component of the .NET runtime that converts intermediate language (IL) code, produced by the .NET compiler, into native machine code that can be executed by the target hardware. It performs this compilation at runtime, just before the IL code is executed, allowing the .NET framework to be platform-independent and enabling performance optimizations based on the specific hardware environment where the application is running. The JIT compiler helps improve the execution speed of .NET applications by dynamically translating IL code into machine code tailored for the underlying system.
To understand the performance values, we have to check what is generated by the JIT compiler. The code that is actually executed by the CPU.
SharpLab
The easiest way to see the code generated by the JIT compiler is to use SharpLab. Let’s use the following code that defines the method Sum() for different types of collections:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
using System;
using System.Collections.Generic;
using System.Collections.Immutable;
static class MyExtensions
{
static int Sum(this int[] source)
{
var sum = 0;
foreach (var item in source)
sum += item;
return sum;
}
static int Sum(this ReadOnlySpan<int> source)
{
var sum = 0;
foreach (var item in source)
sum += item;
return sum;
}
static int Sum(this ImmutableArray<int> source)
{
var sum = 0;
foreach (var item in source)
sum += item;
return sum;
}
static int Sum(this List<int> source)
{
var sum = 0;
foreach (var item in source)
sum += item;
return sum;
}
static int Sum(this IEnumerable<int> source)
{
var sum = 0;
foreach (var item in source)
sum += item;
return sum;
}
}
The ASM generated by the JIT compiler is the following:
MyExtensions.Sum(Int32[])
L0000: xor eax, eax
L0002: xor edx, edx
L0004: mov r8d, [rcx+8]
L0008: test r8d, r8d
L000b: jle short L001c
L000d: mov r9d, edx
L0010: add eax, [rcx+r9*4+0x10]
L0015: inc edx
L0017: cmp r8d, edx
L001a: jg short L000d
L001c: ret
MyExtensions.Sum(System.ReadOnlySpan`1<Int32>)
L0000: xor eax, eax
L0002: mov rdx, [rcx]
L0005: mov ecx, [rcx+8]
L0008: xor r8d, r8d
L000b: test ecx, ecx
L000d: jle short L001e
L000f: mov r9d, r8d
L0012: add eax, [rdx+r9*4]
L0016: inc r8d
L0019: cmp r8d, ecx
L001c: jl short L000f
L001e: ret
MyExtensions.Sum(System.Collections.Immutable.ImmutableArray`1<Int32>)
L0000: xor eax, eax
L0002: mov edx, [rcx+8]
L0005: xor r8d, r8d
L0008: test edx, edx
L000a: jle short L001c
L000c: mov r9d, r8d
L000f: add eax, [rcx+r9*4+0x10]
L0014: inc r8d
L0017: cmp edx, r8d
L001a: jg short L000c
L001c: ret
MyExtensions.Sum(System.Collections.Generic.List`1<Int32>)
L0000: sub rsp, 0x28
L0004: xor eax, eax
L0006: mov edx, [rcx+0x14]
L0009: xor edx, edx
L000b: jmp short L0010
L000d: add eax, r8d
L0010: cmp edx, [rcx+0x10]
L0013: jae short L0039
L0015: mov r8, [rcx+8]
L0019: cmp edx, [r8+8]
L001d: jae short L0046
L001f: mov r9d, edx
L0022: mov r8d, [r8+r9*4+0x10]
L0027: inc edx
L0029: mov r9d, 1
L002f: test r9d, r9d
L0032: jne short L000d
L0034: add rsp, 0x28
L0038: ret
L0039: mov edx, [rcx+0x10]
L003c: inc edx
L003e: xor r8d, r8d
L0041: xor r9d, r9d
L0044: jmp short L002f
L0046: call 0x00007fff90a59ae0
L004b: int3
MyExtensions.Sum(System.Collections.Generic.IEnumerable`1<Int32>)
L0000: push rbp
L0001: push rsi
L0002: sub rsp, 0x38
L0006: lea rbp, [rsp+0x40]
L000b: mov [rbp-0x20], rsp
L000f: xor esi, esi
L0011: mov r11, 0x7fff3e237000
L001b: call qword ptr [r11]
L001e: mov rcx, rax
L0021: mov [rbp-0x10], rcx
L0025: mov r11, 0x7fff3e237008
L002f: call qword ptr [r11]
L0032: test eax, eax
L0034: je short L005e
L0036: mov rcx, [rbp-0x10]
L003a: mov r11, 0x7fff3e237010
L0044: call qword ptr [r11]
L0047: add esi, eax
L0049: mov rcx, [rbp-0x10]
L004d: mov r11, 0x7fff3e237008
L0057: call qword ptr [r11]
L005a: test eax, eax
L005c: jne short L0036
L005e: mov rcx, [rbp-0x10]
L0062: mov r11, 0x7fff3e237018
L006c: call qword ptr [r11]
L006f: mov eax, esi
L0071: add rsp, 0x38
L0075: pop rsi
L0076: pop rbp
L0077: ret
L0078: push rbp
L0079: push rsi
L007a: sub rsp, 0x28
L007e: mov rbp, [rcx+0x20]
L0082: mov [rsp+0x20], rbp
L0087: lea rbp, [rbp+0x40]
L008b: cmp qword ptr [rbp-0x10], 0
L0090: je short L00a3
L0092: mov rcx, [rbp-0x10]
L0096: mov r11, 0x7fff3e237018
L00a0: call qword ptr [r11]
L00a3: nop
L00a4: add rsp, 0x28
L00a8: pop rsi
L00a9: pop rbp
L00aa: ret
You don’t need to understand ASM to find the patterns.
The code generated for int[], ReadOnlySpan<int> and ImmutableArray<int> are very similar.
The code generated for List<int> is longer as it uses a value-type enumerator.
The code generated for IEnumerable<int> is much longer as it uses a reference-type enumerator.
What is surprising is that the generated code for ImmutableArray<int> is not similar to the one of List<int>. We saw above that the IL generated for ImmutableArray<T> uses a value-type enumerator, like List<T>, not an indexer like with an array or a span.
DissassemblyDiagnoser
We can further confirm these findings by checking the output generated by the DisassemblyDiagnoser used with BenchmarkDotNet:
.NET 6.0.20 (6.0.2023.32017), X64 RyuJIT AVX2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
; ForEachBenchmarks.ImmutableArray(
sub rsp,28
; var sum = 0;
; ^^^^^^^^^^^^
xor eax,eax
; foreach (var item in immutableArray!)
; ^^^^^^^^^^^^^^^
add rcx,20
cmp byte ptr [rcx],0
je short M00_L02
mov rdx,[rcx+8]
mov ecx,[rdx+8]
xor r8d,r8d
test ecx,ecx
jle short M00_L01
nop dword ptr [rax]
M00_L00:
movsxd r9,r8d
mov r9d,[rdx+r9*4+10]
; sum += item;
; ^^^^^^^^^^^^
add eax,r9d
inc r8d
cmp ecx,r8d
jg short M00_L00
M00_L01:
add rsp,28
ret
M00_L02:
call System.ThrowHelper.ThrowInvalidOperationException_InvalidOperation_NoValue()
int 3
; Total bytes of code 62)
.NET 8.0.0 (8.0.23.32907), X64 RyuJIT AVX2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
; ForEachBenchmarks.ImmutableArray(
; var sum = 0;
; ^^^^^^^^^^^^
; foreach (var item in immutableArray!)
; ^^^^^^^^^^^^^^^
; sum += item;
; ^^^^^^^^^^^^
; return sum;
; ^^^^^^^^^^^
sub rsp,28
xor eax,eax
add rcx,20
cmp byte ptr [rcx],0
je short M00_L02
mov rdx,[rcx+8]
mov ecx,[rdx+8]
xor r8d,r8d
test ecx,ecx
jle short M00_L01
nop dword ptr [rax]
M00_L00:
mov r9d,r8d
add eax,[rdx+r9*4+10]
inc r8d
cmp ecx,r8d
jg short M00_L00
M00_L01:
add rsp,28
ret
M00_L02:
call qword ptr [7FFF24E149D8]
int 3
; Total bytes of code 60)
The generated ASM code is not exactly the same in both .NET 6 and .NET 8, and not exactly the same as for an array or a span, but it’s very similar to these last two.
Conclusions
The .NET team has been working hard in improving the performance of .NET. They’ve been doing this by adding new performance centric APIs, and by adding many more optimizations at the JIT compiler level.
Optimizations at the JIT level are great because you don’t need to make changes to your code. Not even recompile it. You just need to upgrade the .NET runtime.
I’ve seen many great JIT compiler optimizations, like automatic bounds checking removal, but never one as radical as the seen here for ImmutableArray<T>. This makes ImmutableArray<T> iteration as performant as regular arrays, which is a nice surprise! The performance of creating an ImmutableArray<T> is another subject.
You can also find from the benchmarks is that all the other tests show performance improvements from one version of .NET to another. That’s one great reason to upgrade to .NET 8 as soon as possible.